Writing a Cursor extension to export chat history to Opik
While developing Opik I've been using the Cursor IDE which has been great. However I often run into a couple of problems:
- I can't attach chat logs to PRs - I often want to sync a conversation about a specific part of the code for reviewers to have access to
- I lose track to the conversations linked to each branch
Not sure why I didn't do this before but Opik includes a thread view, why not just sync the Cursor chat conversations to Opik ?
With that, off I went to create the Opik Chat History extension.
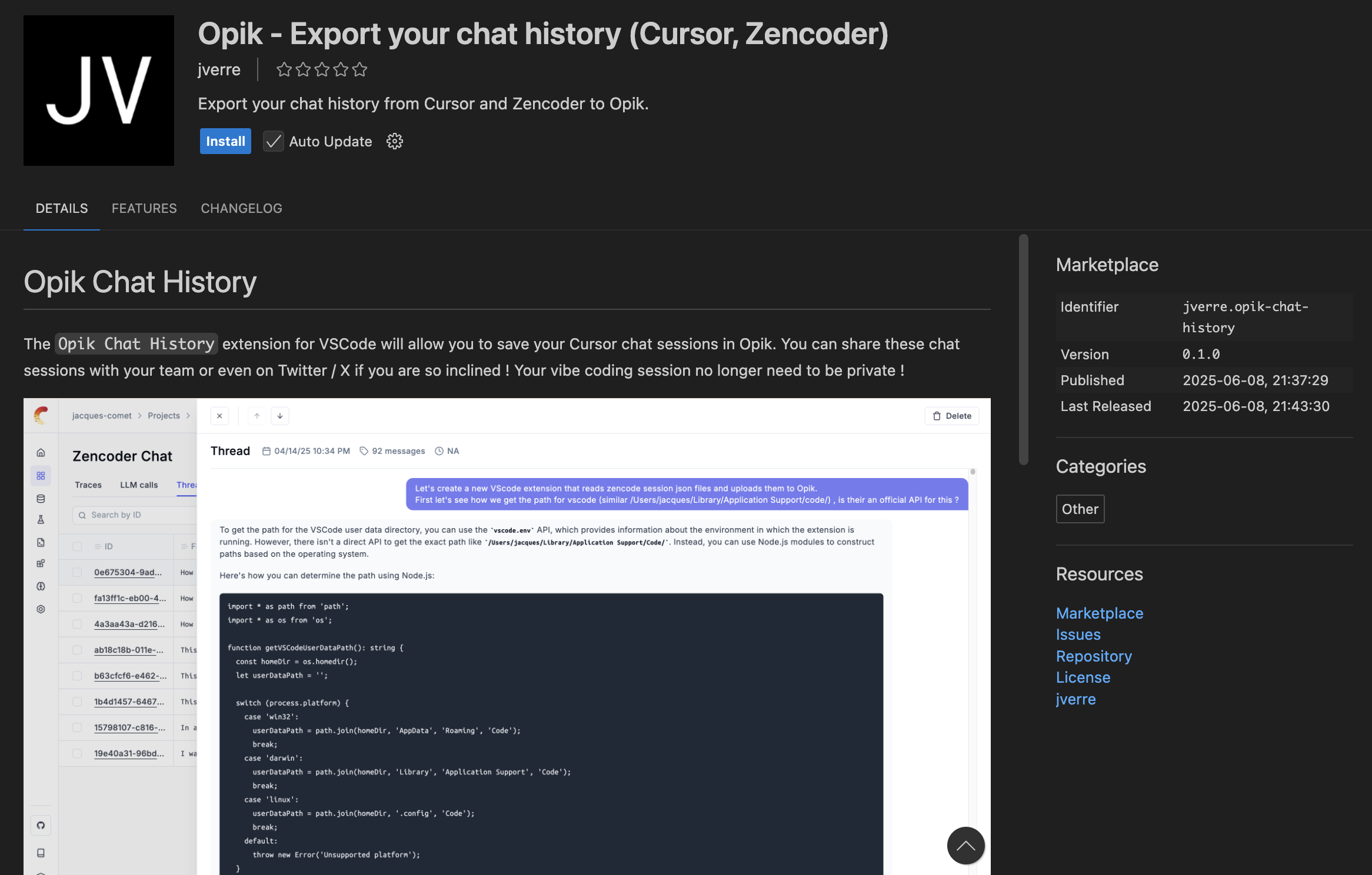
Building a Cursor extension
There is very little information on how to building a Cursor extension but since Cursor is a VS Code fork, we can just follow the VS Code extension guide. The guide is quite straightforward and within an hour I had the extension set up.
Now that we had our dev environment set up and a very simple extension up and running, I wanted to finish creating the end to end user experience. For the final step, I needed to distribute the extension. I thought this would be quite straightforward, just publish it to the VS Code marketplace and you're done. I followed the guides from VS Code and quickly had it listed on the extensions marketplage.
I quickly found out that this doesn't actually list it in the extensions marketplace in Cursor. Cursor uses an alternative marketplace called Open VSX which also does support publishing new extensions. However an issue while logging in to the Eclipse Foundation meant thta I wasn't able to complete the process - Will keep this for a later step.
Now that we have all (well nearly all but that's good enough) components in place, we can start actually writing the extension. As a first step, we need to figure out how to access the Cursor chats.
How Cursor stores data
Where are chats persisted ?
TLDR: The full chat history is stored in a state.vscdb sqlite3 database.
I ran a couple of tests with Cursor to try and figure out how they store the chats. Given that there is no documentation on writing Cursor extensions I thought it might be best to avoid trying to access the data through VSCode and instead try to find where they persist the chats.
After some digging around randomish files and getting nowhere I thought I would try a different technique. I went to uuidgenerator.net, created a random UUID and then pasted that in a Cursor chat. If this data is persisted somewhere, then I could just search from the file or structure that contains it. I ran the first command and waited a little while for the result:
> find "/Users/jacques/Library/Application Support/Cursor/" -type f -exec grep -H "40c67e86-39d2-44e9-bd6e-cf91e8480de6" {} \;
And got no result ... I asked Cursor why this might not work and it (he ?) mentioned that the data could be stored in a binary format as part of a database for example. Interesting, let's try that:
> find "/Users/jacques/Library/Application Support/Cursor/" -type f -exec sh -c '
grep -H "40c67e86-39d2-44e9-bd6e-cf91e8480de6" "{}" || (echo -n "40c67e86-39d2-44e9-bd6e-cf91e8480de6" | xxd -r -p | grep -aob --binary-files=text "{}" 2>/dev/null)
' \;
Binary file /Users/jacques/Library/Application Support/Cursor//User/globalStorage/state.vscdb matches
And bingo we have found a state.vscdb file that contains our unique string. A quick back and forth with Cursor and we
now know this is a sqlite3 file. Couldn't hope for better, we have a database we can read the chats from and there is
not encryption or obfuscation of the chats (looking at you Windsurf ...).
What is the data format of stored chats ?
Now that we know where the data is stored (state.vscdb), we can start to key the data to understand it's structure.
I won't go into all the back and forth on this with Cursor and just jump to the conclusion.
Cursor uses the table cursorDiskKV to store all it's data in a key / value format at the table indicates. Before
we jump into the data schema, it's worth sharing the terminology used by Cursor:
- Composer: This is a conversation or thread
- Bubble: This is the user and ai chat messages
With this information we can jump into the data structure.
Composer data
The conversation metadata is stored in the rows with a key that follows the format composerData:<composerId>. The
value column is a JSON object with the keys:
_v: The version of the payload, currently on version3composerId: The id of the conversationcreatedAt: Creation timestamp in millisecondslastUpdatedAt: Last updated timestamp in millisecondsstatus: The status is eithercompletedorabortedisAgentic: Set to true when inAgentmode and false otherwiselatestConversationSummary: Contains a summary of the conversation so far, this is what is used when you click thenew chatbutton in very long chats. Includes fields likesummary,truncationLastBubbleIdInclusive,clientShouldStartSendingFromInclusiveBubbleIdorlastBubbleIdfullConversationHeadersOnly: This represents the full conversation history and is an array of objects:[{"bubbleId": ..., "type": 1}, {"bubbleId": ..., "type": 2}, ...]s.usageData: Dictionary of cost information per model. Includes acostInCentsfield (makes sense) and aamountfield that I don't know what it represents
And quite a few other fields related to context, files and code blocks that we won't dig into.
{
"_v": 3,
"composerId": "3c73a95c-49a3-47b7-97bb-bbdac4eb6c28",
"richText": "{\"root\":{\"children\":[{\"children\":[],\"direction\":null,\"format\":\"\",\"indent\":0,\"type\":\"paragraph\",\"version\":1}],\"direction\":null,\"format\":\"\",\"indent\":0,\"type\":\"root\",\"version\":1}}",
"hasLoaded": true,
"text": "",
"fullConversationHeadersOnly": [
{
"bubbleId": "2f004b9c-ef06-4c9b-91e5-f018cc83d2c2",
"type": 1
},
{
"bubbleId": "d1e958f5-be27-4dd6-b95e-31087115fade",
"type": 2,
"serverBubbleId": "b7874acd-35f4-427e-97ac-455480d7ce7e"
}
],
"conversationMap": {},
"status": "completed",
"context": {
"notepads": [],
"composers": [],
"quotes": [],
"selectedCommits": [],
"selectedPullRequests": [],
"selectedImages": [],
"folderSelections": [],
"fileSelections": [],
"selections": [],
"terminalSelections": [],
"selectedDocs": [],
"externalLinks": [],
"cursorRules": [],
"uiElementSelections": [],
"mentions": {
"folderSelections": {
"{\"relativePath\":\"/src/cursor\",\"addedWithoutMention\":false}": []
},
"fileSelections": {
"file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/zencoder/zencoderService.ts": []
},
"externalLinks": {
"https://www.comet.com/docs/opik/reference/rest-api/spans/create-spans": []
}
}
},
"codeBlockData": {
"file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts": [
{
"_v": 2,
"bubbleId": "e3292ec6-ce75-4494-aa47-bc064d75fe13",
"codeBlockIdx": 0,
"uri": {
"$mid": 1,
"fsPath": "/Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts",
"external": "file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts",
"path": "/Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts",
"scheme": "file"
},
"version": 0,
"status": "completed",
"languageId": "typescript",
"codeBlockDisplayPreference": "expanded"
}
]
},
"originalModelLines": {
"file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts": [
"import * as path from 'path';",
"import * as vscode from 'vscode';"
]
},
"generatingBubbleIds": [],
"isReadingLongFile": false,
"newlyCreatedFiles": [],
"newlyCreatedFolders": [],
"lastUpdatedAt": 1749380040575,
"createdAt": 1749339221865,
"hasChangedContext": true,
"capabilities": [
{
"type": 15,
"data": {
"bubbleDataMap": "{}"
}
}
],
"name": "Extract timestamp from project data",
"codebaseSearchSettings": {},
"isFileListExpanded": false,
"unifiedMode": "agent",
"forceMode": "edit",
"usageData": {
"claude-4-sonnet-thinking": {
"costInCents": 96,
"amount": 32
}
},
"allAttachedFileCodeChunksUris": [
"file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/opik.ts",
"file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts"
],
"subComposerIds": [],
"latestConversationSummary": {
"summary": {
"summary": "The user initially sought assistance in extracting timestamps from a complex cursor conversation metadata structure...",
"truncationLastBubbleIdInclusive": "142d7fac-61f3-4803-97a7-c65fd9d2be3d",
"clientShouldStartSendingFromInclusiveBubbleId": "1c29bcef-5f00-468d-a21b-eb1bf9d99216"
},
"lastBubbleId": "706bee30-7845-4fe0-bec0-ff10c2d4ac4c"
},
"latestChatGenerationUUID": "a69a8218-b1d8-4e82-84c4-c588a73b7718",
"isAgentic": true
}For the purposes of our extension, the fullConversationHeadersOnly is going to be the most important field.
Bubble data
Bubbles contain significantly more data than conversations, I'm going here to focus only on the most important fields for the extension I'm building:
-
_v: The version of the payload, currently on version2 -
bubbleId: The id of the buggle -
type:1represents a user message and2an AI message -
text: The text displayed to the user -
richText: The Lexical editor state for the text field above, must be used to render the sidebar -
rawText: A simpler representation of the text -
Relevant fields for user messages:
relevantFiles: List of files that are attached by Cursor to the user messsage for examplecontext: Populated with additional informaat likeselections,curosrRules,externalLinks, etccurrentFileLocationData: Information aabout the current location of the user, useful to provide context to the LLM without requiring the uesr to explicitely provide it
-
Relevant fields for ai messages:
thinking: Provides the text behind thethinkingtag in the sidebar andtoolFormerdata: Information about the tool call, this is how filess are edited for example (tool 7is theedit_filetool for example)timingInfo: Contains information about the start and end ofaicallstokenCount: Includes ainputTokensandoutputTokensfield
There are many more fields expecially related to context in user messsage and tool calls in ai messages. I won't cover them here as I just don't know what most of them mean and I don't need them for my extension.
{
"_v": 2,
"type": 2,
"approximateLintErrors": [],
"lints": [],
"codebaseContextChunks": [],
"commits": [],
"pullRequests": [],
"attachedCodeChunks": [],
"assistantSuggestedDiffs": [],
"gitDiffs": [],
"interpreterResults": [],
"images": [],
"attachedFolders": [],
"attachedFoldersNew": [],
"bubbleId": "ee40d28f-3b43-42c6-9d4e-317a7504dd98",
"userResponsesToSuggestedCodeBlocks": [],
"suggestedCodeBlocks": [],
"diffsForCompressingFiles": [],
"relevantFiles": [],
"toolResults": [],
"notepads": [],
"capabilities": [],
"capabilitiesRan": {
"mutate-request": [],
"start-submit-chat": [],
"before-submit-chat": [],
"after-submit-chat": [],
"after-apply": [],
"accept-all-edits": [],
"composer-settled": [],
"composer-done": [],
"process-stream": []
},
"capabilityStatuses": {
"mutate-request": [],
"start-submit-chat": [],
"before-submit-chat": [],
"after-submit-chat": [],
"after-apply": [],
"accept-all-edits": [],
"composer-settled": [],
"composer-done": [],
"process-stream": []
},
"multiFileLinterErrors": [],
"diffHistories": [],
"recentLocationsHistory": [],
"recentlyViewedFiles": [],
"isAgentic": false,
"fileDiffTrajectories": [],
"existedSubsequentTerminalCommand": false,
"existedPreviousTerminalCommand": false,
"docsReferences": [],
"webReferences": [],
"attachedFoldersListDirResults": [],
"humanChanges": [],
"attachedHumanChanges": false,
"summarizedComposers": [],
"cursorRules": [],
"contextPieces": [],
"editTrailContexts": [],
"allThinkingBlocks": [],
"diffsSinceLastApply": [],
"deletedFiles": [],
"supportedTools": [],
"tokenCount": {
"inputTokens": 0,
"outputTokens": 0
},
"attachedFileCodeChunksUris": [],
"consoleLogs": [],
"uiElementPicked": [],
"isRefunded": false,
"knowledgeItems": [],
"documentationSelections": [],
"externalLinks": [],
"useWeb": false,
"projectLayouts": [],
"unifiedMode": 2,
"capabilityContexts": [],
"codeBlocks": [
{
"uri": {
"scheme": "file",
"authority": "",
"path": "/Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts",
"query": "",
"fragment": "",
"_formatted": "file:///Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts",
"_fsPath": "/Users/jacques/Documents/Projects/zencoder-opik-chat-history/src/cursor/sessionManager.ts"
},
"version": 4,
"codeBlockIdx": 0,
"content": "// Helper function to process bubbles in a conversation\nfunction processConversationBubbles(\n conversation: any, \n opikProjectName: string, \n startAppending: boolean, \n lastUploadId: string | undefined\n) {\n const traces: TraceData[] = [];\n let lastMessageId: string | undefined = undefined;\n let lastMessageTime: number | undefined = undefined;\n let shouldAppend = startAppending;\n\n const bubbleGroups = groupBubblesByType(conversation.bubbles);\n\n for (const group of bubbleGroups) {\n // Always update lastMessageId to track our processing position\n const lastMessage = group.aiMessages.length > 0 \n ? group.aiMessages[group.aiMessages.length - 1]\n : group.userMessages[group.userMessages.length - 1];\n \n lastMessageId = lastMessage.id;\n // Extract timestamp inline\n lastMessageTime = lastMessage.timingInfo?.clientEndTime || \n lastMessage.timingInfo?.clientSettleTime ||\n lastMessage.timingInfo?.clientRpcSendTime ||\n lastMessage.timestamp ||\n conversation.lastSendTime || \n Date.now();\n\n // Check if we should start appending from this point\n if (!shouldAppend) {\n // Check both user and AI messages for the lastUploadId\n const hasTargetMessage = [...group.userMessages, ...group.aiMessages]\n .some(msg => msg.id === lastUploadId);\n \n if (hasTargetMessage) {\n shouldAppend = true;\n continue; // Skip this group since it was already processed\n }\n }\n\n if (!shouldAppend) {\n continue;\n }\n\n // Only upload complete conversations (both user and AI messages)\n if (group.userMessages.length > 0 && group.aiMessages.length > 0) {\n const trace = createTraceFromBubbleGroup(group, conversation, opikProjectName);\n if (trace) {\n traces.push(trace);\n }\n }\n // Note: We still track incomplete conversations but don't upload them\n // This ensures we don't miss them in the next round when AI responds\n }\n\n return { traces, lastMessageId, lastMessageTime };\n}\n\n// Helper function to group consecutive bubbles by type\nfunction groupBubblesByType(bubbles: any[]) {\n const groups: { userMessages: any[], aiMessages: any[] }[] = [];\n let i = 0;\n\n while (i < bubbles.length) {\n if (bubbles[i].type !== 'user') {\n i++;\n continue;\n }\n\n const userMessages = [];\n const aiMessages = [];\n\n // Collect consecutive user messages\n while (i < bubbles.length && bubbles[i].type === 'user') {\n userMessages.push(bubbles[i]);\n i++;\n }\n\n // Collect consecutive AI messages\n while (i < bubbles.length && bubbles[i].type === 'ai') {\n aiMessages.push(bubbles[i]);\n i++;\n }\n\n groups.push({ userMessages, aiMessages });\n }\n\n return groups;\n}\n\n// Helper function to create a trace from a bubble group\nfunction createTraceFromBubbleGroup(\n group: { userMessages: any[], aiMessages: any[] },\n conversation: any,\n opikProjectName: string\n): TraceData | null {\n const { userMessages, aiMessages } = group;\n \n // Extract user content inline\n const userContent = userMessages\n .map(msg => msg.text || msg.content || msg.rawText || '')\n .filter(content => content.trim())\n .join('\\n\\n');\n \n // Extract and clean AI content inline\n const assistantContent = aiMessages\n .map(msg => {\n let content = msg.text || msg.content || msg.rawText || '';\n // Clean cursor-specific markup\n return content\n .replace(/⛢Thought☤[\\s\\S]*?⛢\\/Thought☤/g, '')\n .replace(/⛢Action☤[\\s\\S]*?⛢\\/Action☤/g, '')\n .replace(/⛢RawAction☤[\\s\\S]*?⛢\\/RawAction☤/g, '')\n .trim();\n })\n .filter(content => content)\n .join('\\n\\n');\n \n // Filter out traces without proper input or output\n if (!userContent || !assistantContent) {\n return null;\n }\n\n // Extract timestamp inline\n const lastAiMessage = aiMessages[aiMessages.length - 1];\n const endTime = lastAiMessage.timingInfo?.clientEndTime || \n lastAiMessage.timingInfo?.clientSettleTime ||\n lastAiMessage.timingInfo?.clientRpcSendTime ||\n lastAiMessage.timestamp ||\n conversation.lastSendTime || \n Date.now();\n\n // Create metadata inline\n const cleanMessages = (messages: any[]) => \n messages.map(msg => {\n const cleanMsg = { ...msg };\n delete cleanMsg.delegate;\n return cleanMsg;\n });\n\n const metadata = {\n conversationTitle: conversation.chatTitle,\n composerId: conversation.composerId,\n userMessages: cleanMessages(userMessages),\n aiMessages: cleanMessages(aiMessages),\n totalBubbles: conversation.bubbleCount,\n conversationCreatedAt: conversation.createdAt\n };\n\n return {\n name: \"cursor-chat\",\n project_name: opikProjectName,\n start_time: new Date(endTime - 1).toISOString(),\n end_time: new Date(endTime).toISOString(),\n input: { input: userContent },\n output: { output: assistantContent },\n thread_id: conversation.composerId,\n metadata: metadata\n };\n}\n\n// ... existing code ...",
"languageId": "typescript"
}
],
"text": "",
"isThought": false,
"capabilityType": 15,
"toolFormerData": {
"tool": 7,
"toolCallId": "toolu_01N312CpX4DkRtGJdnUVs7cL",
"status": "completed",
"rawArgs": "{\"target_file\": \"src/cursor/sessionManager.ts\", \"instructions\": \"I'll consolidate the smaller helper functions back into the main functions to reduce over-splitting. I'll keep groupBubblesByType separate since it has substantial logic, but inline the simpler functions like extractContent, extractTimestamp, and createMetadata directly into createTraceFromBubbleGroup and processConversationBubbles.\", \"code_edit\": \"// Helper function to process bubbles in a conversation\\nfunction processConversationBubbles(\\n conversation: any, \\n opikProjectName: string, \\n startAppending: boolean, \\n lastUploadId: string | undefined\\n) {\\n const traces: TraceData[] = [];\\n let lastMessageId: string | undefined = undefined;\\n let lastMessageTime: number | undefined = undefined;\\n let shouldAppend = startAppending;\\n\\n const bubbleGroups = groupBubblesByType(conversation.bubbles);\\n\\n for (const group of bubbleGroups) {\\n // Always update lastMessageId to track our processing position\\n const lastMessage = group.aiMessages.length > 0 \\n ? group.aiMessages[group.aiMessages.length - 1]\\n : group.userMessages[group.userMessages.length - 1];\\n \\n lastMessageId = lastMessage.id;\\n // Extract timestamp inline\\n lastMessageTime = lastMessage.timingInfo?.clientEndTime || \\n lastMessage.timingInfo?.clientSettleTime ||\\n lastMessage.timingInfo?.clientRpcSendTime ||\\n lastMessage.timestamp ||\\n conversation.lastSendTime || \\n Date.now();\\n\\n // Check if we should start appending from this point\\n if (!shouldAppend) {\\n // Check both user and AI messages for the lastUploadId\\n const hasTargetMessage = [...group.userMessages, ...group.aiMessages]\\n .some(msg => msg.id === lastUploadId);\\n \\n if (hasTargetMessage) {\\n shouldAppend = true;\\n continue; // Skip this group since it was already processed\\n }\\n }\\n\\n if (!shouldAppend) {\\n continue;\\n }\\n\\n // Only upload complete conversations (both user and AI messages)\\n if (group.userMessages.length > 0 && group.aiMessages.length > 0) {\\n const trace = createTraceFromBubbleGroup(group, conversation, opikProjectName);\\n if (trace) {\\n traces.push(trace);\\n }\\n }\\n // Note: We still track incomplete conversations but don't upload them\\n // This ensures we don't miss them in the next round when AI responds\\n }\\n\\n return { traces, lastMessageId, lastMessageTime };\\n}\\n\\n// Helper function to group consecutive bubbles by type\\nfunction groupBubblesByType(bubbles: any[]) {\\n const groups: { userMessages: any[], aiMessages: any[] }[] = [];\\n let i = 0;\\n\\n while (i < bubbles.length) {\\n if (bubbles[i].type !== 'user') {\\n i++;\\n continue;\\n }\\n\\n const userMessages = [];\\n const aiMessages = [];\\n\\n // Collect consecutive user messages\\n while (i < bubbles.length && bubbles[i].type === 'user') {\\n userMessages.push(bubbles[i]);\\n i++;\\n }\\n\\n // Collect consecutive AI messages\\n while (i < bubbles.length && bubbles[i].type === 'ai') {\\n aiMessages.push(bubbles[i]);\\n i++;\\n }\\n\\n groups.push({ userMessages, aiMessages });\\n }\\n\\n return groups;\\n}\\n\\n// Helper function to create a trace from a bubble group\\nfunction createTraceFromBubbleGroup(\\n group: { userMessages: any[], aiMessages: any[] },\\n conversation: any,\\n opikProjectName: string\\n): TraceData | null {\\n const { userMessages, aiMessages } = group;\\n \\n // Extract user content inline\\n const userContent = userMessages\\n .map(msg => msg.text || msg.content || msg.rawText || '')\\n .filter(content => content.trim())\\n .join('\\\\n\\\\n');\\n \\n // Extract and clean AI content inline\\n const assistantContent = aiMessages\\n .map(msg => {\\n let content = msg.text || msg.content || msg.rawText || '';\\n // Clean cursor-specific markup\\n return content\\n .replace(/⛢Thought☤[\\\\s\\\\S]*?⛢\\\\/Thought☤/g, '')\\n .replace(/⛢Action☤[\\\\s\\\\S]*?⛢\\\\/Action☤/g, '')\\n .replace(/⛢RawAction☤[\\\\s\\\\S]*?⛢\\\\/RawAction☤/g, '')\\n .trim();\\n })\\n .filter(content => content)\\n .join('\\\\n\\\\n');\\n \\n // Filter out traces without proper input or output\\n if (!userContent || !assistantContent) {\\n return null;\\n }\\n\\n // Extract timestamp inline\\n const lastAiMessage = aiMessages[aiMessages.length - 1];\\n const endTime = lastAiMessage.timingInfo?.clientEndTime || \\n lastAiMessage.timingInfo?.clientSettleTime ||\\n lastAiMessage.timingInfo?.clientRpcSendTime ||\\n lastAiMessage.timestamp ||\\n conversation.lastSendTime || \\n Date.now();\\n\\n // Create metadata inline\\n const cleanMessages = (messages: any[]) => \\n messages.map(msg => {\\n const cleanMsg = { ...msg };\\n delete cleanMsg.delegate;\\n return cleanMsg;\\n });\\n\\n const metadata = {\\n conversationTitle: conversation.chatTitle,\\n composerId: conversation.composerId,\\n userMessages: cleanMessages(userMessages),\\n aiMessages: cleanMessages(aiMessages),\\n totalBubbles: conversation.bubbleCount,\\n conversationCreatedAt: conversation.createdAt\\n };\\n\\n return {\\n name: \\\"cursor-chat\\\",\\n project_name: opikProjectName,\\n start_time: new Date(endTime - 1).toISOString(),\\n end_time: new Date(endTime).toISOString(),\\n input: { input: userContent },\\n output: { output: assistantContent },\\n thread_id: conversation.composerId,\\n metadata: metadata\\n };\\n}\\n\\n// ... existing code ...\"}",
"name": "edit_file",
"params": "{\"relativeWorkspacePath\":\"src/cursor/sessionManager.ts\",\"contents\":\"// Helper function to process bubbles in a conversation\\nfunction processConversationBubbles(\\n conversation: any, \\n opikProjectName: string, \\n startAppending: boolean, \\n lastUploadId: string | undefined\\n) {\\n const traces: TraceData[] = [];\\n let lastMessageId: string | undefined = undefined;\\n let lastMessageTime: number | undefined = undefined;\\n let shouldAppend = startAppending;\\n\\n const bubbleGroups = groupBubblesByType(conversation.bubbles);\\n\\n for (const group of bubbleGroups) {\\n // Always update lastMessageId to track our processing position\\n const lastMessage = group.aiMessages.length > 0 \\n ? group.aiMessages[group.aiMessages.length - 1]\\n : group.userMessages[group.userMessages.length - 1];\\n \\n lastMessageId = lastMessage.id;\\n // Extract timestamp inline\\n lastMessageTime = lastMessage.timingInfo?.clientEndTime || \\n lastMessage.timingInfo?.clientSettleTime ||\\n lastMessage.timingInfo?.clientRpcSendTime ||\\n lastMessage.timestamp ||\\n conversation.lastSendTime || \\n Date.now();\\n\\n // Check if we should start appending from this point\\n if (!shouldAppend) {\\n // Check both user and AI messages for the lastUploadId\\n const hasTargetMessage = [...group.userMessages, ...group.aiMessages]\\n .some(msg => msg.id === lastUploadId);\\n \\n if (hasTargetMessage) {\\n shouldAppend = true;\\n continue; // Skip this group since it was already processed\\n }\\n }\\n\\n if (!shouldAppend) {\\n continue;\\n }\\n\\n // Only upload complete conversations (both user and AI messages)\\n if (group.userMessages.length > 0 && group.aiMessages.length > 0) {\\n const trace = createTraceFromBubbleGroup(group, conversation, opikProjectName);\\n if (trace) {\\n traces.push(trace);\\n }\\n }\\n // Note: We still track incomplete conversations but don't upload them\\n // This ensures we don't miss them in the next round when AI responds\\n }\\n\\n return { traces, lastMessageId, lastMessageTime };\\n}\\n\\n// Helper function to group consecutive bubbles by type\\nfunction groupBubblesByType(bubbles: any[]) {\\n const groups: { userMessages: any[], aiMessages: any[] }[] = [];\\n let i = 0;\\n\\n while (i < bubbles.length) {\\n if (bubbles[i].type !== 'user') {\\n i++;\\n continue;\\n }\\n\\n const userMessages = [];\\n const aiMessages = [];\\n\\n // Collect consecutive user messages\\n while (i < bubbles.length && bubbles[i].type === 'user') {\\n userMessages.push(bubbles[i]);\\n i++;\\n }\\n\\n // Collect consecutive AI messages\\n while (i < bubbles.length && bubbles[i].type === 'ai') {\\n aiMessages.push(bubbles[i]);\\n i++;\\n }\\n\\n groups.push({ userMessages, aiMessages });\\n }\\n\\n return groups;\\n}\\n\\n// Helper function to create a trace from a bubble group\\nfunction createTraceFromBubbleGroup(\\n group: { userMessages: any[], aiMessages: any[] },\\n conversation: any,\\n opikProjectName: string\\n): TraceData | null {\\n const { userMessages, aiMessages } = group;\\n \\n // Extract user content inline\\n const userContent = userMessages\\n .map(msg => msg.text || msg.content || msg.rawText || '')\\n .filter(content => content.trim())\\n .join('\\\\n\\\\n');\\n \\n // Extract and clean AI content inline\\n const assistantContent = aiMessages\\n .map(msg => {\\n let content = msg.text || msg.content || msg.rawText || '';\\n // Clean cursor-specific markup\\n return content\\n .replace(/⛢Thought☤[\\\\s\\\\S]*?⛢\\\\/Thought☤/g, '')\\n .replace(/⛢Action☤[\\\\s\\\\S]*?⛢\\\\/Action☤/g, '')\\n .replace(/⛢RawAction☤[\\\\s\\\\S]*?⛢\\\\/RawAction☤/g, '')\\n .trim();\\n })\\n .filter(content => content)\\n .join('\\\\n\\\\n');\\n \\n // Filter out traces without proper input or output\\n if (!userContent || !assistantContent) {\\n return null;\\n }\\n\\n // Extract timestamp inline\\n const lastAiMessage = aiMessages[aiMessages.length - 1];\\n const endTime = lastAiMessage.timingInfo?.clientEndTime || \\n lastAiMessage.timingInfo?.clientSettleTime ||\\n lastAiMessage.timingInfo?.clientRpcSendTime ||\\n lastAiMessage.timestamp ||\\n conversation.lastSendTime || \\n Date.now();\\n\\n // Create metadata inline\\n const cleanMessages = (messages: any[]) => \\n messages.map(msg => {\\n const cleanMsg = { ...msg };\\n delete cleanMsg.delegate;\\n return cleanMsg;\\n });\\n\\n const metadata = {\\n conversationTitle: conversation.chatTitle,\\n composerId: conversation.composerId,\\n userMessages: cleanMessages(userMessages),\\n aiMessages: cleanMessages(aiMessages),\\n totalBubbles: conversation.bubbleCount,\\n conversationCreatedAt: conversation.createdAt\\n };\\n\\n return {\\n name: \\\"cursor-chat\\\",\\n project_name: opikProjectName,\\n start_time: new Date(endTime - 1).toISOString(),\\n end_time: new Date(endTime).toISOString(),\\n input: { input: userContent },\\n output: { output: assistantContent },\\n thread_id: conversation.composerId,\\n metadata: metadata\\n };\\n}\\n\\n// ... existing code ...\",\"blocking\":true,\"instructions\":\"I'll consolidate the smaller helper functions back into the main functions to reduce over-splitting. I'll keep groupBubblesByType separate since it has substantial logic, but inline the simpler functions like extractContent, extractTimestamp, and createMetadata directly into createTraceFromBubbleGroup and processConversationBubbles.\",\"shouldEditFileFailForLargeFiles\":false}",
"additionalData": {
"version": 4,
"startingLints": [],
"lintingStatus": "linted"
},
"userDecision": "accepted",
"result": "{\"diff\":{\"chunks\":[{\"diffString\":\" \\n lastMessageId = lastMessage.id;\\n- lastMessageTime = extractTimestamp(lastMessage, conversation);\\n+ // Extract timestamp inline\\n+ lastMessageTime = lastMessage.timingInfo?.clientEndTime || \\n+ lastMessage.timingInfo?.clientSettleTime ||\\n+ lastMessage.timingInfo?.clientRpcSendTime ||\\n+ lastMessage.timestamp ||\\n+ conversation.lastSendTime || \\n+ Date.now();\\n \\n // Check if we should start appending from this point\",\"oldStart\":75,\"newStart\":75,\"oldLines\":5,\"newLines\":11,\"linesRemoved\":1,\"linesAdded\":7},{\"diffString\":\" const { userMessages, aiMessages } = group;\\n \\n- const userContent = extractContent(userMessages);\\n- const assistantContent = cleanAndExtractContent(aiMessages);\\n- \\n- // Filter out traces without proper input or output\\n- if (!userContent || !assistantContent) {\\n- return null;\\n- }\\n- \\n- const endTime = extractTimestamp(aiMessages[aiMessages.length - 1], conversation);\\n- const metadata = createMetadata(conversation, userMessages, aiMessages);\\n- \\n- return {\\n- name: \\\"cursor-chat\\\",\\n- project_name: opikProjectName,\\n- start_time: new Date(endTime - 1).toISOString(),\\n- end_time: new Date(endTime).toISOString(),\\n- input: { input: userContent },\\n- output: { output: assistantContent },\\n- thread_id: conversation.composerId,\\n- metadata: metadata\\n- };\\n- }\\n- \\n- // Helper function to extract content from messages\\n- function extractContent(messages: any[]): string {\\n- return messages\\n+ // Extract user content inline\\n+ const userContent = userMessages\\n .map(msg => msg.text || msg.content || msg.rawText || '')\\n .filter(content => content.trim())\\n .join('\\\\n\\\\n');\\n- }\\n \\n- // Helper function to clean and extract AI content\\n- function cleanAndExtractContent(messages: any[]): string {\\n- return messages\\n+ // Extract and clean AI content inline\\n+ const assistantContent = aiMessages\\n .map(msg => {\\n let content = msg.text || msg.content || msg.rawText || '';\",\"oldStart\":311,\"newStart\":317,\"oldLines\":38,\"newLines\":12,\"linesRemoved\":30,\"linesAdded\":4},{\"diffString\":\" .filter(content => content)\\n .join('\\\\n\\\\n');\\n- }\\n- \\n- // Helper function to extract timestamp from message\\n- function extractTimestamp(message: any, conversation: any): number {\\n- return message.timingInfo?.clientEndTime || \\n- message.timingInfo?.clientSettleTime ||\\n- message.timingInfo?.clientRpcSendTime ||\\n- message.timestamp ||\\n+ \\n+ // Filter out traces without proper input or output\\n+ if (!userContent || !assistantContent) {\\n+ return null;\\n+ }\\n+ \\n+ // Extract timestamp inline\\n+ const lastAiMessage = aiMessages[aiMessages.length - 1];\\n+ const endTime = lastAiMessage.timingInfo?.clientEndTime || \\n+ lastAiMessage.timingInfo?.clientSettleTime ||\\n+ lastAiMessage.timingInfo?.clientRpcSendTime ||\\n+ lastAiMessage.timestamp ||\\n conversation.lastSendTime || \\n Date.now();\\n- }\\n \\n- // Helper function to create metadata\\n- function createMetadata(conversation: any, userMessages: any[], aiMessages: any[]) {\\n+ // Create metadata inline\\n const cleanMessages = (messages: any[]) => \\n messages.map(msg => {\",\"oldStart\":356,\"newStart\":336,\"oldLines\":18,\"newLines\":20,\"linesRemoved\":11,\"linesAdded\":13},{\"diffString\":\" });\\n \\n- return {\\n+ const metadata = {\\n conversationTitle: conversation.chatTitle,\\n composerId: conversation.composerId,\",\"oldStart\":377,\"newStart\":359,\"oldLines\":5,\"newLines\":5,\"linesRemoved\":1,\"linesAdded\":1},{\"diffString\":\" conversationCreatedAt: conversation.createdAt\\n };\\n+ \\n+ return {\\n+ name: \\\"cursor-chat\\\",\\n+ project_name: opikProjectName,\\n+ start_time: new Date(endTime - 1).toISOString(),\\n+ end_time: new Date(endTime).toISOString(),\\n+ input: { input: userContent },\\n+ output: { output: assistantContent },\\n+ thread_id: conversation.composerId,\\n+ metadata: metadata\\n+ };\\n }\\n \",\"oldStart\":385,\"newStart\":367,\"oldLines\":4,\"newLines\":15,\"linesAdded\":11}]},\"isApplied\":true,\"numLinesInFile\":388,\"isSubagentEdit\":false}"
},
"checkpointId": "4d55c51f-4133-4a68-ba36-794f5cfa8498",
"afterCheckpointId": "fd4ae662-5d8a-4759-9a00-2ee318098639"
}With the information we have collected above we can now go ahead and create our extension.
Writing the extension
I won't cover the writing of the extension in detail, I simply used the information gathered above and asked Cursor to log the data to Opik. You can find the full code on Github. I did learn a few things as I built the extension that I thought might be worth sharing.
Testing as you go is key:
I quickly found that Cursor had a tendency to write code that ran but didn't produce the desired effect, for example it would send duplicated messages to Opik. When I asked Cursor to fix it, it always did but the isssue is that I still needed to know when to do that. I ended up implementing a small script that would clear the cache and log the data to a new project each time I refreshed the extension, this was incredibly helpful in catching regressions.
Adding error logging for "production" catches the errors you missed
I didn't spend much time testing the application, I made sure it worked for all my chats but I didn't look further.
Makes sense, afterall this is an evening project and to be honest I don't even know how to write tests in Typescript.
But I do still care about the overall quality of the app and so I implemented PostHog to catch issues I might have
missed. At first I used PostHog exception autocapture feature but quickly turned that off when I realised that
due to the way extensions are run I would catch every error from every extension installed... Once it was properly
configured, I could solve the bugs aas they appeared.
Cursor doesn't know what it doesn't know
Cursor, or perhaps more appropriately Claude 4, has a tendency to find a solution to any task you give it even if it
doesn't have the right information to answer it. More than a few times, Cursor went down a rabbit hole of if statements
and conditional logic just because it didn't know the structure of a Bubble field for example.
Thank you Cursor for sponsoring my LLM addiction!
Once I had all the token usage information logged in Opik I could look at my usage in more detail. Writing the extension took a whoping 2,000,000 tokens in just 2 days ! That's $30 dollars if you pay public prices for Claude 4... The $20/month plan is a bargain.
Next steps
Now that the extension is live, I'll start working on improving the data that is captured. Currently the
extension only captures the text but not attached files, codeblockss and other information. This will
be part of version 0.2.0 of the extension.